Spark의 핵심 데이터 소스
- TXT
- CSV
- JSON
- 파케이 (Parquet)
- ORC
- JDBC/ODBC
- TXT 파일
텍스트 파일은 컴퓨터 파일 시스템에서 컴퓨터 파일의 일종으로 사람이 인지할 수 있는 문자열 집합으로부터 문자열로만 이루어진다.
잘 알려진 문자열 집합으로는 ASCII 문자열 집합과 유니코드 문자열 집합이 있다.
- CSV 파일
csv는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일로 흔히 사용되며 비교적 단순한 파일 포맷이다.
예시)
연도,제조사,모델,설명,가격
1997,Ford,E350,"ac, abs, moon",3000.00
1999,Chevy,"Venture ""Extended Edition"",4900.00
1999,Chevy,"Venture ""Extended Edition, Very Large"",,5000.00
1996,Jeep,Grand Cherokee,"MUST SELL!air, moon roof, loaded",4799.00
- JSON 파일
JSON(JavaScript Object Notation)은 속성-값 쌍 또는 키-값 쌍으로 이루어진 데이터 오브젝트를 전달하기 위해 인간이 읽을 수 있는 텍스트를 사용하는 개방형 표준 포맷이다.
본래는 자바스크립트 언어로부터 파생되어 자바스크립트의 구문 형식을 따르지만 언어 독립형 데이터 포맷이다. 따라서 C, C++, C#, 자바, 펄, 파이썬 등 다양한 프로그래밍 언어에서 이용할 수 있다.
예시)
{
"이름": "홍길동",
"나이": 25,
"성별": "남",
"주소": "서울특별시 양천구 목동",
"특기": ["농구", "도술"],
"가족관계": {"#": 2, "아버지": "홍판서", "어머니": "춘섬"},
"회사": "경기 수원시 팔달구 우만동"
}
- 파케이 (Parquet) 파일
파케이는 열 기반 데이터 저장 형식으로 우수한 압축률과 스키마 암호화를 유지하므로 방대한 양의 데이터를 처리하기에 효율적인 포맷이다.
파케이 파일 형식은 중첩 데이터를 더 잘 저장할 수 있다. HDFS 과 같이 저장된 데이터에 더 많은 계층이 있는 경우 파케이는 데이터를 트리 구조처럼 최적의 결과로 저장할 수 있다.
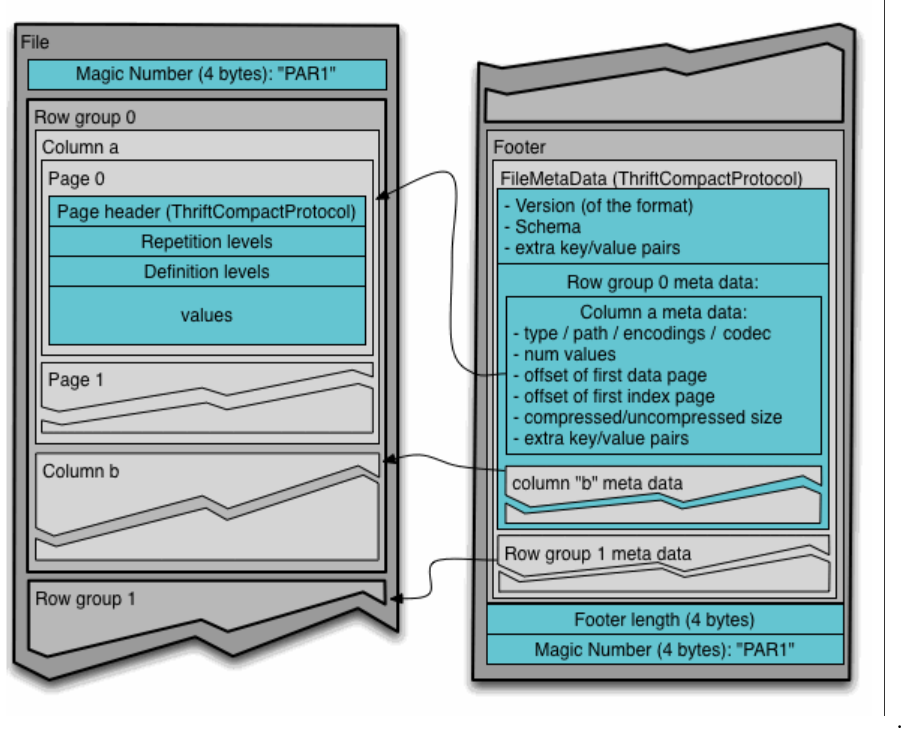
Parquet Header, Data Block, Parquet Footer 3가지 구조로 구성되어 있으며 각각의 역할은
Parquet Header
파일 형식 처리가 parquet 유형임을 나타냄
Data Block
column chunk와 column metadata로 구성된 레코드 그룹
column chunk는 페이지로 더 나뉘며 각 페이지는 주어진 데이터 세트에 있는 특정 레코드의 특정 열 값으로 구성된다.
column metadata에는 유형, 경로, 인코딩 유형, 값, 수, 압축 크기와 같은 열 정보가 포함된다.
Parquet Footer
Footer의 메타데이터는 형식의 버전, 데이터 블록의 스키마, 모든 키-값 쌍 및 데이터 블록에 있는 각 열의 메타데이터로 구성된다.
- ORC 파일
ORC(Optimized Row Columnar)는 자기 기술적이며 데이터 타입을 인식할 수 있는 칼럼 기반의 파일.
1. 대규모 스트리밍 읽기에 최적화 되어있다.
2. 필요한 로우를 신속하게 찾아낼 수 있는 기능이 통합되어 있다.

ORC 파일에는 파일 바닥글의 보조 정보와 함께 스트라이프라고 하는 행 데이터 그룹이 포함되어 있으며 파일 끝 PostScript는 압축 매개변수와 압축된 바닥글의 크기를 포함한다.
- JDBC/ODBC
JDBC : 자바가 데이터베이스를 액세스하기 위한 응용프로그램 인터페이스인 Java API를 말함.
ODBC : 데이터베이스를 액세스하기 위한 소프트웨어의 표준 규격으로 개방형 응용 인터페이스를 말함.
이외에도 다른 커뮤니티에서 만든 수많은 데이터 소스가 존재한다.
카산드라, HBase, MongoDB, AWS RedShift, XML, 기타 수많은 데이터 소스
Reference
https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:%EB%8C%80%EB%AC%B8
위키백과, 우리 모두의 백과사전
위키백과:대문 위키백과, 우리 모두의 백과사전. 위키백과 우리 모두가 만들어가는 자유 백과사전문서 580,432개와 최근 기여자 2,255명 사랑방 다른 분들과 의견을 교환해봐요! 질문방 지침으로
ko.wikipedia.org
https://parquet.apache.org/documentation/latest/
Apache Parquet
Motivation We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem. Parquet is built from the ground up with complex nested data structures in mind, and uses the recor
parquet.apache.org
https://www.learntospark.com/2020/02/how-to-read-and-write-parquet-in-apache-spark.html
Parquet File Format | Spark Optimization Technique
Spark Performance Tuning, Architectural Overview of Apache Parquet file format and how to read and write or save the parquet file using PySpark
www.learntospark.com
https://cwiki.apache.org/confluence/display/hive/languagemanual+orc
LanguageManual ORC - Apache Hive - Apache Software Foundation
ORC Files ORC File Format Version Introduced in Hive version 0.11.0. The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files im
cwiki.apache.org
'빅데이터' 카테고리의 다른 글
| [PySpark] PostgreSQL 연동하기 (4) | 2022.03.22 |
|---|---|
| [PySpark] Spark 구성 컴포넌트 (0) | 2022.03.08 |
| [PySpark] Spark 란? (0) | 2022.03.07 |
| Yolov5를 이용한 TFT 챔피언 인식하기 (0) | 2022.02.18 |
| API를 활용한 챗봇 만들기 (0) | 2022.02.07 |




댓글