
Spark란?
아파치 스파크는 하둡의 맵리듀스를 대체하는 새로운 빅데이터 처리 플랫폼.
일관 처리 기능, 실시간 데이터 처리 기능, SQL과 유사한 정형 데이터 처리 기능, 그래픽 알고리즘, 머신 러닝 알고리즘을 모두 단일 프레임워크에 통합했다.
- 장점
- 자바, 스칼라, 파이썬, R 언어 지원
- 맵리듀스에 비해 최대 100배 빠른 수행 (인 메모리 실행)
- 데이터 처리 작업에 적합한 함수형 프로그래밍 방식 활용 가능
- 단점
- 소량의 적은 데이터셋 연산에 비효율적
- 온라인 트랜잭션 처리(OLTP) 애플리케이션으로 설계되지 않아 대량의 원자성 트랜잭션을 빠르게 처리해야 하는 경우 적합하지 않다.
- 일반적으로 Spark가 하는 일
일반 컴퓨터 한대로 수행하기 힘든 대규모 정보를 컴퓨터 클러스터(컴퓨터 여러대를 한대로 만든 것 비유하자면 비트코인 채굴소)를 만들었고 그 클러스터 작업 조율을 하는 프레임워크가 스파크이며, 쉽게 말해 스파크는 클러스터의 데이터 처리 작업을 관리하고 조율한다.
스파크가 연산에 사용할 클러스터는 스파크 스탠드얼론 클러스터 매니저, 하둡 YARN, 메소스 같은 클러스터 매니저에서 관리한다.
유저는 클러스터 매니저에 스파크 애플리케이션을 제출하고 제출받은 클러스터 매니저는 애플리케이션 실행에 필요한 자언을 할당하며 우리는 할당 받은 자원으로 작업을 처리한다.
Spark Architecture
아키텍쳐란 컴퓨터 시스템의 핵심 구조로 쉽게 설명하면 컴퓨터 구성 요소간의 이식되는 것들과 요구사항들이 무엇인지 기능적으로 설명되어 있는 청사진으로 생각하면 된다.

- 스파크 애플리케이션
스파크 애플리케이션은 드라이버 프로세스 + 다수의 익스큐터 프로세스로 구성된다.
드라이버 프로세스는 클러스터 노드 중 하나에서 실행되며 main()함수를 실행한다. 이는 스파크 애플리케이션 정보의 유지 관리, 사용자 프로그램이나 입력에 대한 응답, 전반적인 익스큐퍼 프로세스의 작업과 관련된 분석, 배포, 스케줄링 역할을 수행한다. 즉 드라이버 프로세스는 스파크 애플리케이션의 심장과 같은 존재로 애플리케이션의 수명 주기 동안 관련 정보를 모두 유지한다.
익스큐터는 드라이버 프로세스가 할당한 작업을 수행한다.
- SparkSession
스파크 애플리케이션은 SparkSession이라 불리는 드라이버 프로세스로 제어한다. SparkSession 인스턴스는 사용자가 정의한 처리 명령을 클라스터에서 실행하며 SparkSession은 하나의 스파크 애플리케이션에 대응한다.
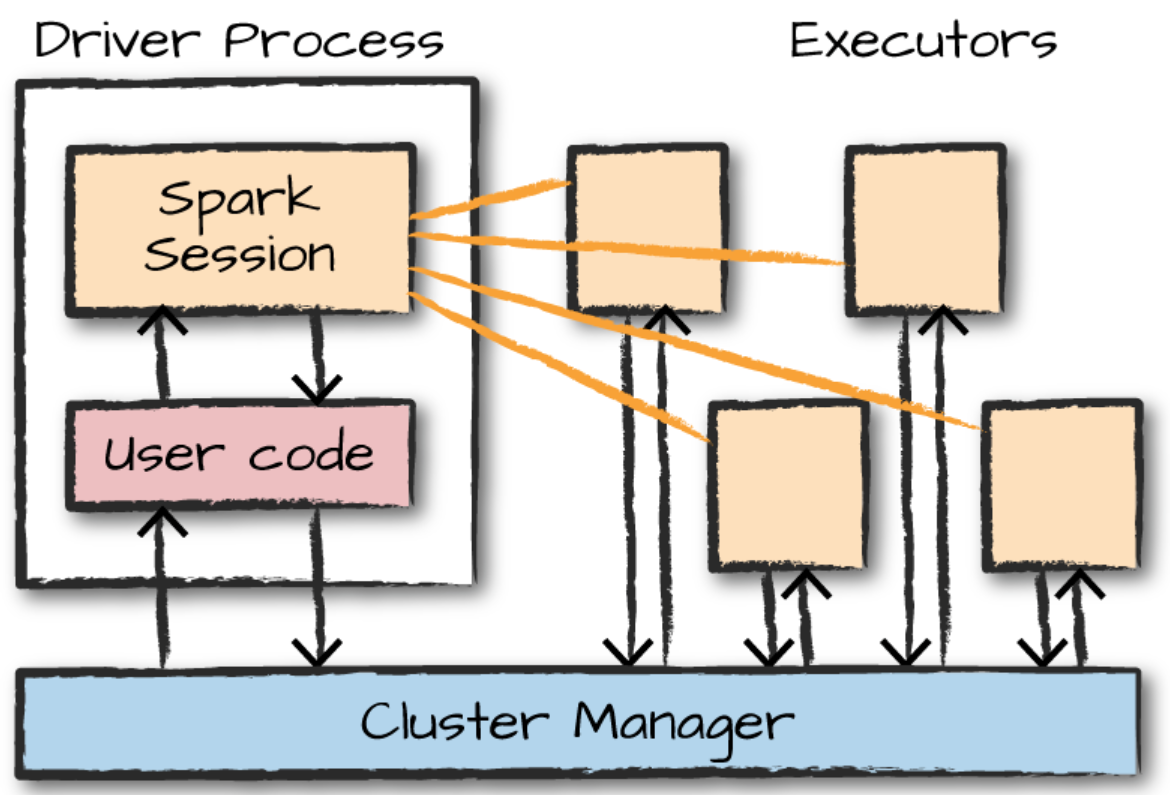
대화형 모드로 스파크를 실행 시 스파크 애플리케이션을 관리하는 SparkSession이 자동으로 생성된다. 하지만 스탠드얼론 애플리케이션인 경우 사용자 애플리케이션 코드에서 SparkSession 객체를 직접 생성해야 한다.
- 스파크는 어떻게 다양한 언어를 지원하는 걸까?
스파크에서는 스칼라, 자바, 파이썬, SQL, R을 지원하는데 스칼라는 스파크의 기본 언어이지만 자바, 파이썬, R 과 같은 다른 언어 API는 어떻게 지원하는 걸까? 정답은 JVM에 있다. 스파크 창시자들은 자바를 이용해 스파크 코드를 작성할 수 있도록 개발하였고 그 결과 R, Python과 같은 다른 언어가 JVM에서 익스큐터가 실행할 수 있는 코드로 변환하기 때문에 가능하다.
'빅데이터' 카테고리의 다른 글
| [PySpark] PostgreSQL 연동하기 (4) | 2022.03.22 |
|---|---|
| [PySpark] Spark 핵심 DataSource (0) | 2022.03.09 |
| [PySpark] Spark 구성 컴포넌트 (0) | 2022.03.08 |
| Yolov5를 이용한 TFT 챔피언 인식하기 (0) | 2022.02.18 |
| API를 활용한 챗봇 만들기 (0) | 2022.02.07 |




댓글