회귀모델로 LinearRegression(), Ridge(), ElasticNet(), RandomForestRegressor(), GradientBoostingRegressor(), Lasso(), LGBMRegressor() 을 활용
Modeling
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.linear_model import ElasticNet, Lasso, Ridge, LinearRegression
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
X = X_train[features]
y = y_train
models = [LinearRegression(), Ridge(), ElasticNet(), RandomForestRegressor(), GradientBoostingRegressor(), Lasso(), LGBMRegressor()]
rmses, maes, r2s = [], [], []
for model in models:
pipe = make_pipeline(StandardScaler(), model)
y_preds = cross_val_predict(pipe, X, y, cv=cv, n_jobs=-1)
rmse = np.sqrt(mean_squared_error(y_train, y_preds))
mae = mean_absolute_error(y_train, y_preds)
r2 = r2_score(y_train, y_preds)
rmses.append(rmse)
maes.append(mae)
r2s.append(r2)
pd.DataFrame({"RMSE": rmses,"MAE": maes,"R2": r2s}, index=models).sort_values(by="R2", ascending=False)
HyperParameter Tuning
# RandomizedSearchCV
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
parameters = {
"gradientboostingregressor__learning_rate": [1, 0.5, 0.25, 0.1, 0.05, 0.01],
"gradientboostingregressor__n_estimators": [1, 2, 4, 8, 16, 32, 64, 100, 200, 500],
"gradientboostingregressor__max_depth": np.arange(1, 33),
}
pipe = make_pipeline(StandardScaler(), GradientBoostingRegressor())
rand_grid = RandomizedSearchCV(pipe, parameters, n_iter=100, scoring="r2", n_jobs=-1, cv=3, verbose=1)
rand_grid.fit(X_train, y_train)
print()
print(f"Best parameters: {rand_grid.best_params_}")
print(f"Best parameters: {rand_grid.best_score_:.4f}")
# GridSearchCV
parameters = {
"gradientboostingregressor__learning_rate": [0.03, 0.04, 0.05, 0.06, 0.07],
"gradientboostingregressor__n_estimators": [180, 190, 200, 210, 220],
"gradientboostingregressor__max_depth": [1, 2, 3, 4],
}
grid = GridSearchCV(pipe, parameters, scoring="r2", n_jobs=-1, cv=3, verbose=1)
grid.fit(X_train, y_train)
print()
print(f"Best parameters: {grid.best_params_}")
print(f"Best parameters: {grid.best_score_:.4f}")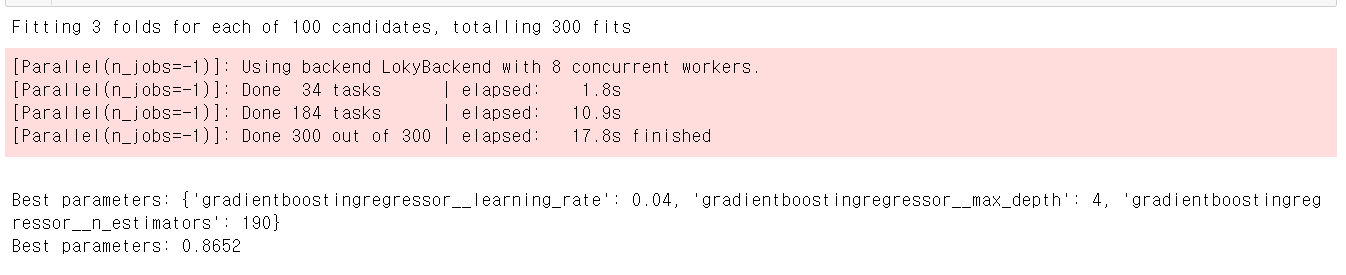
GridSearchCV에서 더 좋은 지표를 얻었다.
Final predictions & submission
learning_rate = grid.best_params_['gradientboostingregressor__learning_rate']
max_depth = grid.best_params_['gradientboostingregressor__max_depth']
n_estimators = grid.best_params_['gradientboostingregressor__n_estimators']
pipe = make_pipeline(StandardScaler(), GradientBoostingRegressor(learning_rate=learning_rate, max_depth=max_depth, n_estimators=n_estimators))
pipe.fit(X_train, y_train)
y_preds = pipe.predict(X_test)
y_predspredictions = pd.DataFrame({"Id": test_data["Id"], "SalePrice": y_preds})
predictions.head()
predictions.to_csv("output.csv", index=False)
Reference
- Select Features
http://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/
- Negative_MSE
https://techblog-history-younghunjo1.tistory.com/105
- PCA
https://www.kaggle.com/vinayaktiwari28/simplest-approach-pca-to-reduce-dimensions
[ML] Regression metric과 Polynominal Regression 구현하기
이번 포스팅에서는 회귀분석(Regression) 모델의 성능 평가에 이용되는 평가지표(metric)과 Polynominal Regression(다항 회귀분석)를 Python으로 구현하는 방법에 대해 알아보려고 한다. 목차는 다음과 같다.
techblog-history-younghunjo1.tistory.com
Sequential Feature Selector - mlxtend
From here you can search these documents. Enter your search terms below.
rasbt.github.io
Simplest approach-[PCA to reduce dimensions]]
Explore and run machine learning code with Kaggle Notebooks | Using data from House Prices - Advanced Regression Techniques
www.kaggle.com
'데이터 분석 > Kaggle' 카테고리의 다른 글
| House Price (4) - 변수 선택 (0) | 2022.01.04 |
|---|---|
| House Price (3) - EDA (0) | 2022.01.03 |
| House Price (2) - 결측치 확인 및 처리 (0) | 2021.12.21 |
| House Price (1) - 데이터 설명 (0) | 2021.12.20 |




댓글