
Random Forest
소개
랜덤포레스트는 분류 및 회귀 ML 중 하나로 앙상블 학습 방법의 일종으로 트리 기반 알고리즘이다. 각 트리들은 랜덤하게 서로 다른 특성을 가진다. 이를 통해 각 트리들의 예측이 비상관적이며 결과적으로 일반화 성능을 향상시킨다.
<진행과정>

랜덤화
랜덤화는 각 트리들의 훈련 과정에서 진행되며, 랜덤 학습 데이터 추출 방법을 이용한 앙상블 학습법인 배깅(bagging)과 랜덤 노드 최적화(randomized node optimization)가 자주 사용된다. 이 두 가지 방법은 서로 동시에 사용되어 랜덤화 특성을 더욱 증진 시킬 수 있다.
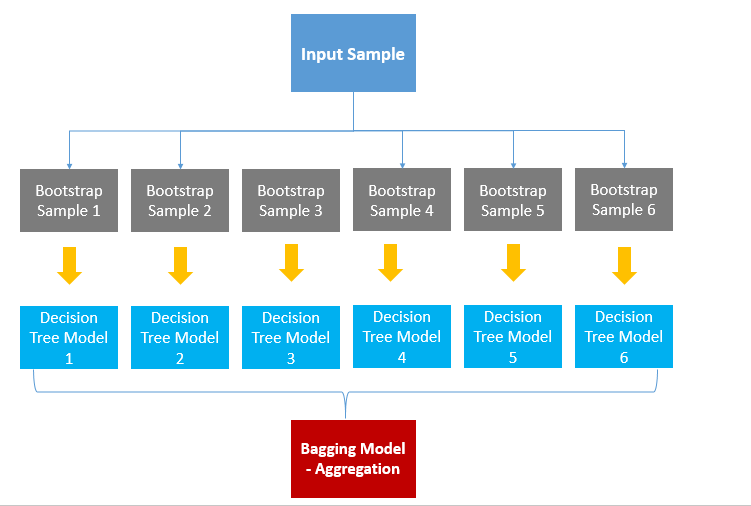
배깅 (Bagging)
랜덤 샘플링한 데이터를 여러 모델에 학습시킨 뒤 결과를 집계하는 방식

Bootstrap Sampling
데이터셋에서 여러 작은 데이터셋을 임의로 복원추출하여 생성하여 개별 평균의 분포도를 측정하는 목적을 위한 샘플링 방식

OOB (Out of Bag)
일반적으로 배깅 방식은 데이터셋의 2/3을 훈련 데이터로 사용한다. 나머지 1/3을 OOB(Out-of-Bag)관측치라 한다
OOB 오차
OOB와 훈련 데이터셋의 예측과의 차이를 OOB 오차라고 하며 이 오차가 배깅 방식에서 평가 수단으로 사용된다. 이 OOB 오차를 통해 OOB 스코어를 계산한다.
변수 중요도
랜덤 포레스트 알고리즘에서 제공하는 기능으로 변수의 중요도를 확인 가능하다. 변수의 중요도를 파악하는 방법은 어떤 변수가 분할 변수로 사용되고 사용된 후의 불순도(오차제곱합 or 지니계수)가 많이 감소되는 크기를 구한 후 평균을 통해 산출.
< 예시 : 타이타닉 생존 >

Reference
[1] https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
sklearn.ensemble.RandomForestClassifier
Examples using sklearn.ensemble.RandomForestClassifier: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.22 Release Highlights...
scikit-learn.org
[2] https://ko.wikipedia.org/wiki/%EB%9E%9C%EB%8D%A4_%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8
랜덤 포레스트 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 기계 학습에서의 랜덤 포레스트(영어: random forest)는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로부
ko.wikipedia.org
[3] https://medium.com/nerd-for-tech/random-forest-sturdy-algorithm-d60b9f9140d4
Random Forest — Sturdy algorithm.
Decision Tree has many problems like greedy algorithm, overfitting, low predictions accuracy and calculations can become complex, when…
medium.com
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| XGBoost (0) | 2022.10.07 |
|---|---|
| 부스팅 알고리즘 (Boosting Algorithm) (2) | 2022.10.05 |
| 앙상블(Ensemble) (0) | 2022.10.02 |
| 결정 트리(Decision Tree) (0) | 2022.09.25 |
| 유튜브 댓글 분석하기 (0) | 2022.06.15 |




댓글