유튜브 댓글을 워드클라우드로 표현하여 어떤 단어가 많이 쓰였는지 알아봅시다.
본 과정은 Colab 환경에서 진행하였으며 댓글 작성자 및 저작권 침해 우려로 인해 분석 결과물은 넣지 않았습니다.
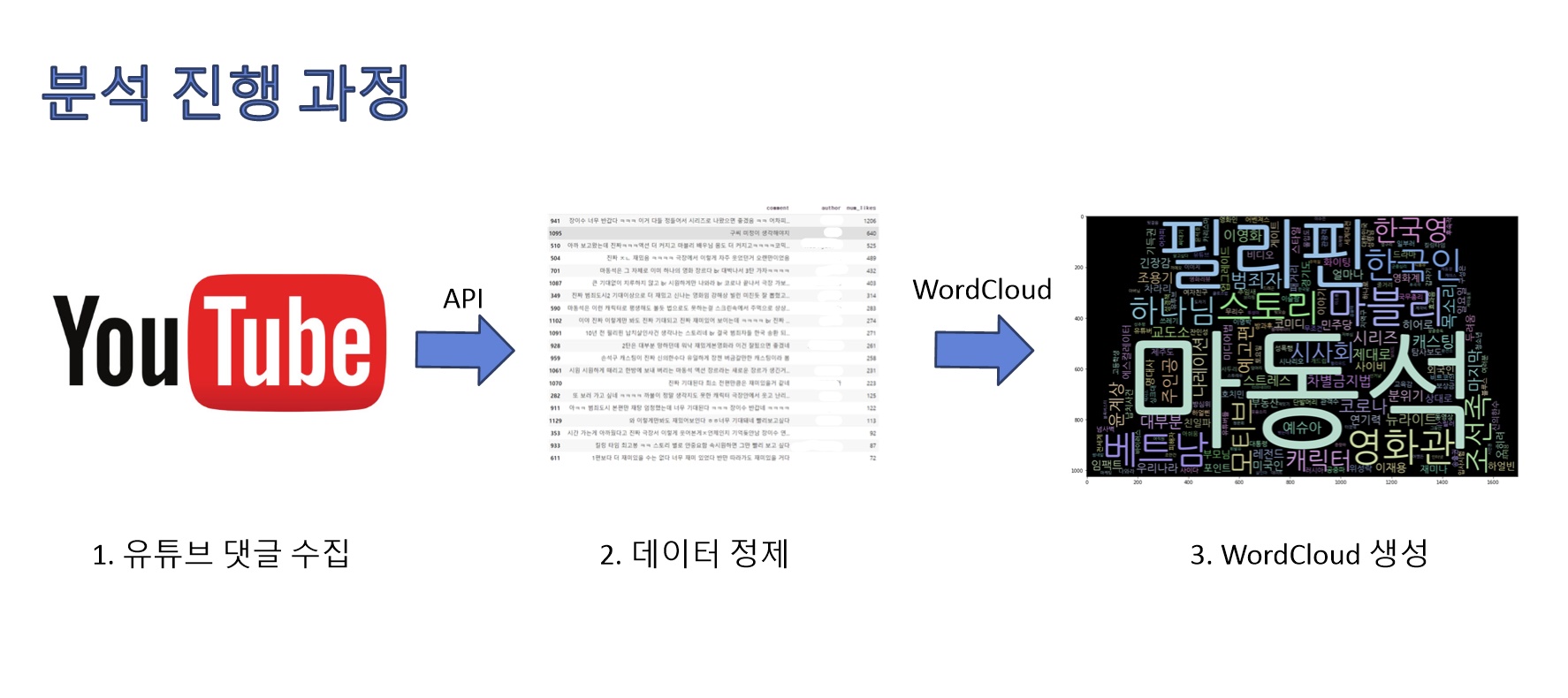
1. 유튜브 댓글 수집하기
pip install google-api-python-client
pip install konlpy# 글꼴 설정
!apt-get update -qq
!apt-get install fonts-nanum* -qq
import matplotlib.font_manager as fm
import warnings
warnings.filterwarnings(action='ignore')
path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 나눔 고딕### install modules
import re
from googleapiclient.discovery import build
from konlpy.tag import Okt
from tqdm import tqdm
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
from konlpy.tag import Okt
from PIL import Image
import numpy as np
import pandas as pd
import warnings # 경고창 무시
warnings.filterwarnings('ignore')유튜브 링크 주소 입력
links = input("유튜브 링크 전체 주소를 입력해주세요. \n ex) https://www.youtube.com/watch?v=xx-xxxxxxxxx \n\n")
if len(links) > 47 or len(links) < 41:
print("다시 입력해주시기 바랍니다.")
else:
video_id = links.replace("https://www.youtube.com/watch?v=", "")아래의 api_key는 구글 클라우드 플랫폼 혹은 아래 블로그를 참조하여 확인 바랍니다.
https://han-py.tistory.com/432
[youtube api] 유튜브 데이터 가져오기
유튜브의 영상데이터를 가지고 와서 브라우저에 보여주는 방법을 알아보자. 만약 react나 nodejs를 통해 구축환경을 고려하고 있다면, 아래의 url을 참고하자. [Web/nodejs] - nodejs 기초 총 정리 기본적
han-py.tistory.com
## 아래 코드에서 주로 사용되는 변수 -- 개인 정보 포함되어 있으므로 추후 배포시 수정요망
api_key = 'API 키' # 구글 API 키
comment_num = 400 # 댓글 갯수# 댓글을 저장할 리스트
comments = list()
# developerKey = API 키
api_obj = build('youtube', 'v3', developerKey=api_key)
# videoId는 각 유튜브 영상 url의 watch?v 뒤의 값을 사용
response = api_obj.commentThreads().list(part='snippet', videoId=video_id, maxResults=comment_num).execute()# 댓글, 댓글작성자, 좋아요 수
while response:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['likeCount']])
# 다음 페이지가 있는 경우 재호출
if 'nextPageToken' in response:
response = api_obj.commentThreads().list(part='snippet', videoId=video_id, pageToken=response['nextPageToken'], maxResults=comment_num).execute()
else:
breakdf = pd.DataFrame(comments, columns=['comment','author','num_likes'], index=None)
2. 수집한 데이터 정제하기
# 특수문자 제거하기
df['comment'] = df['comment'].str.replace(pat=r'[^\w]', repl=r' ', regex=True)
# 특정문자 제거하기
df['comment'] = df['comment'].str.replace(pat=r'br', repl=r' ', regex=True)
df['comment'] = df['comment'].str.replace(pat=r'quot', repl=r' ', regex=True)
df['comment']
좋아요를 많이 받은 댓글 top 20
# 좋아요를 많이 받은 글 top 20
likes = df.sort_values(by='num_likes', ascending=False)
likes.head(20)# 불필요한 단어 제거하기
# 불용어
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다','br','a','href','https','www','youtube','com','watch','v']# 토큰화 하면서 불용어 제거하기
okt = Okt()
comment_token = []
for comment in tqdm(df['comment']):
tokenized_comment = okt.nouns(comment) # 명사만 토큰화
stopwords_removed_comment = [word for word in tokenized_comment if not word in stopwords] # 불용어 제거
comment_token.append(stopwords_removed_comment)# 리스트 평탄화
words = sum(comment_token, [])
t_words = [n for n in words if len(n) > 2] # 단어의 길이가 1개인 것은 제외
c = Counter(t_words)3. WordCloud 생성하기
# 색깔 보정
def color_func(word, font_size, position,orientation,random_state=None, **kwargs):
return("hsl({:d},{:d}%, {:d}%)".format(np.random.randint(30,313),np.random.randint(26,62),np.random.randint(65,80)))# img는 wordcloud의 모양 형태에 쓰임
img = Image.open('pic2.jpg')
img_array = np.array(img)
wc = WordCloud(font_path=path, width=400, height=400, scale=2.0, max_font_size=250, background_color='black',color_func = color_func, mask=img_array)
gen = wc.generate_from_frequencies(c)
plt.figure(figsize=(20,10))
plt.imshow(gen)## save
likes.to_csv("result.csv", index=None)
Reference
[youtube api] 유튜브 데이터 가져오기
유튜브의 영상데이터를 가지고 와서 브라우저에 보여주는 방법을 알아보자. 만약 react나 nodejs를 통해 구축환경을 고려하고 있다면, 아래의 url을 참고하자. [Web/nodejs] - nodejs 기초 총 정리 기본적
han-py.tistory.com
[시각화] 파이썬으로 한글 워드클라우드(Word Cloud) 생성하고 원하는 이미지 형태로 출력하기
안녕하세요. 오늘 소개해드릴 코드는 한글 문서의 단어를 추출하여 워드클라우드(Word Cloud)로 시각화하는 방법입니다. 파이썬에서 시각화는 거의 모두 matplotlib 라이브러리를 기반으로 하고 있습
doitgrow.com
Word cloud 원하는 색으로 꾸미기 (word cloud customize color)
분석대회를 끝내고, 발표자료를 준비하는데 워드클라우드로 시각화를 한 이미지가 생각보다 안 예쁘더랍니다. ppt 테마 색 같은 걸 정해놓은 경우엔 미적 감각이 없는 제가 봐도, 이런 부조화가
wannabe00.tistory.com
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| 앙상블(Ensemble) (0) | 2022.10.02 |
|---|---|
| 결정 트리(Decision Tree) (0) | 2022.09.25 |
| [PySpark] 숙박업 분석 - (3) ML (0) | 2022.04.14 |
| Numpy의 함수를 사용한 서바이벌 게임 (0) | 2022.02.24 |
| 월별 출생건수 (2) - 외국 사례 (0) | 2022.01.08 |




댓글